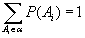 (B.001)
(B.001)=== *** === *** ===
В данном руководстве приведены основные сведения из теории вероятностей, рассчитанные на учащихся старших классов средних школ, студентов технических ВУЗов и техникумов. Предполагается, что читатели знакомы с основами математического анализа.
В руководстве доказательства не приводятся. Материалы разделов B.4 и B.5 при первом прочтении можно пропустить.
Статистика изучает числовые значения, чтобы обнаружить в них закономерности. При этом закономерности бывают достоверными (детерминированными) и случайными (недетерминированными, стохастическими). Примерами детерминированных закономерностей являются:
Как правило, достоверные закономерности можно вычислить с помощью формул и/или точных алгоритмов.
Наоборот, случайные события не могут быть выражены формулой. Например, мы не можем точно указать:
Ответы на подобные вопросы можно получить, только проведя соответствующие испытания. Поэтому дадим определения случайным («стохастическим») событиям:
Стохастические события – это события, результат которых не полностью определяется влияющими на него факторами, оставляя некоторую неопределённость в своём значении.
Для описания явлений с неопределённым исходом используется идея случайности. Согласно этой идее, результат стохастического исхода определяется неким случайным испытанием, случайным экспериментом, случайным выбором. Вопрос о том, насколько применим такой подход к стохастическим событиям, решается по результатам практического применения.
В большинстве явлений присутствуют оба вида изменчивости: и закономерная, и случайная. Для нахождения закономерностей нам приходится «отсеивать» мешающие случайные факторы. Правильным «отсевом» этих факторов занимается такая дисциплина, как «планирование эксперимента».
Однако случайности могут не только мешать нахождению закономерностей – они способны сами порождать их. Например, предсказать движение всех молекул газа в сосуде не представляется возможным. Однако вся их совокупность ведёт себя вполне закономерно, подчиняясь уравнению Клайперона-Менделеева. Давление газа на площадь сосуда постоянно, и обратно пропорционально его объёму.
Аналогично, время и длительность телефонных звонков выбирает сам абонент, но нагрузка на АТС, распределение перерывов между звонками – закономерное событие. Изучением закономерностей, порождаемых случайными событиями, занимается наука «теория вероятностей».
Хотя результат эксперимента, опыта, зависящего от случайных факторов, нельзя предсказать, его возможные исходы (события, результаты) имеют неодинаковые шансы на появление. Количественной мерой «правдоподобия» – появления определённого события, является вероятность. Если A – случайное событие, то вероятность его появления обозначается как P(A). Вероятность – величина нормированная. Для любого события 0 <= P(A) <= 1, причём P(A) = 0, если A – невозможное событие, и P(A) = 1, если A – достоверное (детерминированное) событие. Для всех возможных событий Ai из множества α существует следующая формула нормировки:
(B.001)
Таким образом, вероятности всех исходов не может быть больше единицы.
Приведём пример использования теории вероятностей на птицефабрике. Учащиеся школ, знакомящиеся с птицефабрикой на экскурсии, часто задают вопрос: «А как узнать, сколько кур и сколько петушков вылупиться из яиц»? К своему удивлению, они слышат следующий ответ: «А мы всегда заранее знаем и планируем, сколько кур и петухов выводится в инкубаторе при закладке в него яиц. Дело в том, что вероятность получения из яйца курицы равна 49%, а петушков – 51%. Поэтому если положить в инкубатор, допустим, сто яиц, то из них вылупится 49 курочек и 51 петушок».
Действительно, предсказать, какой цыплёнок вылупится из конкретного яйца, проблематично. Но совокупный результат – всегда предсказуемое явление.
Объединением, или суммой случайных событий A и B называют событие C, которое происходит тогда или только тогда, когда происходит событие A, B или оба вместе. Его обозначение:
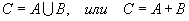 (B.002)
(B.002)
Пересечением, или произведением событий A и B называют событие C, которое происходить только в том случае, если возможны оба события, A и B. Его обозначение:
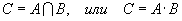 (B.003)
(B.003)
Отрицанием события A называют такое событие, которое состоит в том, что не происходит события A. Оно обозначается как – A.
Событие, которое при нашем случайном испытании обязательно происходит, называется достоверным событием, а которое невозможно осуществить – невозможным событием. По этому определению:
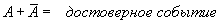 – достоверное событие, (B.004), а
– достоверное событие, (B.004), а
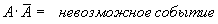 – невозможное событие (B.005).
– невозможное событие (B.005).
Если события A и B не могут произойти одновременно (т.е. A·B – невозможное событие), то их называют несовместными событиями. Для несовместных событий верны формулы:
P(A·B) = 0 (B.006)
P(A+B) = P(A) + P(B) (B.007)
В общем случае, для суммы вероятностей событий A и B применима следующая формула:
P(A+B) = P(A) + P(B) - P(A·B) (B.008)
Для полного описания случайного опыта нужно указать на все его возможные исходы и вероятности.
Например, однократное бросание игральное кости, имеющей форму куба, приводит к выпадению одной из шести её граней. Это шесть элементарных исходов кости, т. е неразложимые на более простые исходы (события). Если при розыгрыше лотереи вынимается каждый раз один шар (из 36), то выбор каждого шара – также элементарный исход. Если кость, как говорят, правильная, розыгрышные шары хорошо перемешаны, то:
Таким образом, мы получили одну из важнейших правил теории вероятностей:
Вероятность каждого элементарного исхода из n возможных исходов (и связанного с ним события) равна 1/n
Вероятность события A, которое наступает при наступлении m элементарных исходов из n возможных, будет равна m/n:
P(A) = m/n (B.009)
(При первом прочтении это доказательство можно пропустить)
Выразим условную вероятность случайного испытания с конечным числом элементарных исходов. Пусть число всех элементарных исходов Ω, а ω – произвольный элементарный исход, и вероятность этого исхода P(ω). Любые события A и B являются подмножества множества Ω. Обозначим P(A|B) условную вероятность события A при условии, что произошло событие B. При исходах ω, не входящих в событие B, невозможны при наступлении события B, поэтому условная вероятность исхода omega при событии B:
P(ω|B) = 0, если ω не входит в B (B.010)
Для исходов ω, при которых наступает событие B, сумма их вероятностей должна равняться P(B):
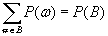 (B.011)
(B.011)
а сумма их условных вероятностей:
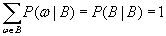 (B.012)
(B.012)
Чтобы одновременно выполнялись обе нормировки, необходимо, чтобы
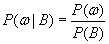 (B.013)
(B.013)
Таким образом, получим следующее определение условной вероятности A при наступлении события B:
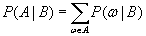 (B.014)
(B.014)
Событие A не зависит от события B, если:
P(A|B) = P(A) (B.015)
Если некоторое событие может произойти, а может и не произойти, то оно называется случайным событием, а количественной характеристикой его появления является вероятность. Случайные события могут быть совместными (когда они могут произойти вместе друг с другом) и несовместными (когда эти события «не пересекаются»), независимыми (когда вероятность появления одного случайного события не зависит от другого) и условными (когда вероятность наступления одного события вычисляется некоторой функцией от другого события). Из этих соображений вытекает следующее определение вероятностей, приведённое в [1]:
Если при некоторых условиях должно произойти одно из n несовместных независимых случайных событий, причём нет оснований предполагать, что одно из них предпочтительней другого, то говорят, что эти события имеют одинаковую вероятность, равную:
P = 1/n (B.016)
Если некоторое случайное событие A появляется как следствие одного из m событий при общем числе n возможных исходов (несовместных и равновероятных), то вероятностью события A называют число:
P = m/n (B.017)
Невозможному событию соответствует вероятность 0, а достоверному событию – вероятность 1. Вероятность любого события P находится в диапазоне:
0 < P < 1 (B.018)
Если вероятность события B зависит от того, произойдёт или нет событие A, то такую вероятность называют условной вероятностью, а события – зависимыми. Условная вероятность определяется как P(B|A).
Проиллюстрировать условную вероятность условную вероятность можно следующим образом.
Пусть у нас есть корзина с n шарами, из которых m шаров белых, а остальные – чёрные шары. Предположим, что мы берём шары наугад, и если шар белый, мы выбираем следующий шар, не возвращая выбранный белый шар обратно в корзину. Если шар чёрный, то мы возвращаем его в корзину и выбираем следующий шар.
Таким образом, в нашем случае вероятность «вытянуть» чёрный и белый шар после белого шара – условная вероятность, а вероятность «вытянуть» любой шар после чёрного – безусловная вероятность.
=== *** === *** ===
Совместные события – события, которые могут происходить совместно друг с другом. Например, если вероятность попадания пули в цель стрелком равна 60%, то вероятность попадания пуль в цель, после двух попыток, будет больше 60%, но не равна 120%. Это объясняется тем, что хотя вероятности попадания в цель независимы, однако взяты из одной выборки, т.е. могут происходить совместно. Вероятность же стрелка попасть в цель после двух попыток равна 84% (см. формулу сложения совместных вероятностей ниже).
Вероятность появления какого-либо одного (безразлично какого) из нескольких независимых несовместных событий A и B равна сумме вероятностей этих событий.
P = P(A) + P(B) (B.019)
Вероятность совместного появления нескольких независимых событий равна произведению вероятностей этих событий:
P = P(A)·P(B) (B.020)
Если вероятность события B зависит от того, произошло или нет событие А, то такую вероятность условной вероятностью и обозначают следующим образом: P(B|A). В этом случае формулы сложения и умножения вероятностей (для зависимых несовместных событий) будут следующими:
P(B) = P(B|A)·P(A) (B.021)
P(AB) = P(B|A)·P(A)2 (B.022)
P(A+B) = P(A)·(P(B|A)+1) (B.023)
Если два события не зависимы друг от друга, но могут произойти одновременно, то суммарная вероятность наступления хотя бы одного из них будет равна:
P(A+B) = P(A) + P(B) - P(A)·P(B) (B.024)
Вероятность их совместного появления будет по-прежнему вычисляться по формуле (B.020).
=== *** === *** ===
Как видно из формул (B.011) – (B.024), число коэффициентов и при вычислении условных и/или совместных вероятностей возрастает. Причём это возрастание сложности делает невозможным применение простых формул (B.019) и (B.020), а сами функции вычисления вероятностей оказываются перегружены множественными коэффициентами. Поэтому в теории вероятностей ввели понятие функции распределения вероятности, которые позволяют при помощи ограниченного числа независимых параметров рассчитать любую вероятность наступления событий.
Если мы ввели понятие вероятности как количественное выражение правдоподобия случайного события, то нам необходимы методы её измерения. Здесь возможны пути умозрения и прямого измерения.
Умозрительный способ определения вероятности основан на понятии «элементарного исхода».
Элементарный исход – это неразложимый на более простые события результат эксперимента.
Однако у умозрительного принципа есть следующие недостатки:
Поэтому «в чистом» виде умозрительный способ расчёта вероятностей используется только в приложении к случайному выбору, лотереям и азартным играм.
Измерение вероятности события отличается от измерения других физических величин. Физические величины измеряются приборами. Для вероятности такого прибора нет. Измерение вероятности основано на независимых повторениях случайного эксперимента.
Пусть в случайном опыте нас интересует вероятность события А. При правильно спланированном случайном опыте вероятность события A не меняется. Проведём N таких испытаний (реализаций) этого опыта. Это число выбирается заранее. Подсчитаем число тех опытов из N, в которых событие произошло – N(A). Тогда по теореме Бернулли [Анализ данных на компьютере], отношение N(A)/N приблизительно равно P(A), если число повторений N велико.
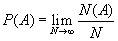 (B.025)
(B.025)
Итак, задав вопрос об измерении вероятностей, мы столкнулись с неожиданностью – это измерение оказалось, во-первых, непростым с физической точки зрения (многократное повторение при неизменных условиях), а во-вторых, сопряжённым с довольно сложными и новыми понятиями.
Особо следует подчеркнуть, что описанные выше опыты должны:
Все эти факторы затрудняют получение результатов измерения вероятности, особенно если требуется высокая точность этого измерения.
Как уже сказано выше, если искомая вероятность не является ни независимой, ни несовместной, при расчёте нужно пользоваться функциями распределения вероятностей. Приведём пример использования такой функции.
... Во время Великой Отечественной войны, при бомбёжке Ленинграда, в зоопарке бомба попала в слона. Это позволило некоторым неосведомлённым «критикам» теории вероятностей заявить о невозможности такого события. Они утверждали: «Если разделить площадь слона на площадь Ленинграда, то получим почти нулевую вероятность этого события». Однако это утверждение справедливо лишь в том случае, если бы немецкие бомбардировщики сбрасывали бомбы куда ни попади. На деле же положение вещей объясняется следующим образом.
В то время зоопарк находился в центре города, вблизи трёх мостов. Поскольку мосты – цели бомбардировки, а зоопарк находился в зоне 60% попадания бомбы в цель, вероятность попадания бомбы в слона не является призрачной.
Итак, для объяснения этого факта достаточно изменить функцию равномерного распределения вероятностей на «колокол» кривой Гаусса (с центром в области этих трёх мостов).
Функции распределения вероятностей бывают дискретными (определённых на ограниченном целом числе испытаний) и непрерывными (определённых на непрерывном, почти бесконечном множестве вещественных чисел).
В случайных опытах нас часто интересуют величины, имеющие числовое значение. Чтобы подчеркнуть то обстоятельство, что численное значение измеряемой по ходу опыта величины зависит от его случайного исхода, саму полученную величину называют случайной величиной. Случайной величиной, в частности, является упомянутое выше число очков, выпадающее при бросании игральной кости, сумма очков, выпадающая при бросании двух игральных костей (а также их разность, произведение и т.д.).
Каждая случайная величина задаёт распределение вероятностей на множестве своих значений. Если ξ – случайная величина, принимающая значение из множества X, то мы можем задать распределение вероятностей Pξ на X следующим образом:
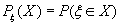 (B.026)
(B.026)
Чтобы дать полное математическое описание случайной величины, надо указать множество её значений и соответствующее ей распределение вероятностей на этом множестве.
Случайные величины бывают дискретными и непрерывными.
Дадим следующее определение дискретных случайных величин:
Случайную величину называют дискретной, если множество её возможных значений конечное либо счётное.
Примечание. Множество называется счётным, если его элементы можно пронумеровать натуральными числами.
Каждое возможное значение дискретной случайной величины имеют положительную (иногда и нулевую) вероятность.
Однако не все случайные величины могут быть описаны как дискретные случайные величины. Например, время службы электронной лампочки может, в общем, принимать значения от нуля до бесконечности. И если предполагается, что лампочка была в начале исправна, вероятность того, что время её службы будет в точности равно определённому значению, будет равна нулю. Однако вероятность того, что лампочка будет работать в точном промежутке времени (например, от одного до двух месяцев) – величина не нулевая.
Таким образом, дадим следующее определение непрерывной функции распределения случайной величины:
Пусть ξ обозначает случайную величину, принимающую вещественное значение, X – вещественное число. Тогда функцией распределения F(X) случайной величины ξ называют:
F(X) = P(ξ < X) (B.027)
Ясно, что F(X) – не убывающая функция, принимающая значения от 0 до 1.
У дискретной случайной величины эта функция ступенчатая; там, где её вероятность положительна, наблюдаются её разрывы (скачки).
Определение:
Случайную величину, принимающую вещественные значения называют непрерывной, если непрерывна её функция распределения.
Нагляднее всего непрерывную случайную величину можно представить тогда, когда функция её распределения не только непрерывна, но и дифференцируема (от неё можно найти производную функцию, за исключением, может быть, конечного числа точек). В этом случае вероятности связанных с данной случайной величиной событий можно выразить с помощью, так называемой функцией плотности вероятности.
Функция p(t) называется плотностью вероятности в точке t (иногда – плотностью случайной величины ξ), если для любых чисел A и B (A < B)
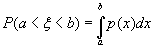 (B.028)
(B.028)
Для любого Δ > 0 и любого действительного t
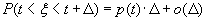 (B.029)
(B.029)
где o(Δ) – бесконечно малая по сравнению с Δ величина.
Функция распределения и плотность распределения связаны соотношениями:
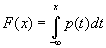 (B.030)
(B.030)
p(x) = F'(x) (B.031)
Из этих определений находим следующие свойства функции плотности вероятности p(t):
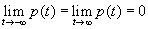 (B.032)
(B.032)
 (B.033)
(B.033)
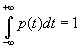 (B.034)
(B.034)
Уравнение (B.033) указывает на не убывание функции F(x), уравнение (B.032) – на ограниченность этой функции, а (B.034) – условие нормировки функции p(t). Кроме того, функция p(t) для непрерывных распределений также функция ограниченная.
Также, если в точке x функция распределения y = F(x) имеет скачок, величина этого скачка равна вероятности, сосредоточенной в точке x, то есть вероятности события ξ = x. Если же в точке x функция F(x) непрерывна, имеет производную и касательную, то тангенс угла наклона касательной равен плотности вероятности p(x) в этой точке.
=== *** === *** ===
Числовые характеристики распределения вероятностей полезны тем, что позволяют составить наглядное представление об этом распределении. Наиболее употребимые из этих характеристик – моменты и квантили. Простейшие, широко используемые на практике способы их определения, представлены ниже, в п. B.3.2.1 и п. B.3.2.2..
Начнём с так называемого первого момента случайной величины ξ, называемого также математическим ожиданием, или средним значением ξ. Его обозначают как Mξ. Оно вычисляется по формуле:
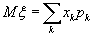 (B.035)
(B.035)
для дискретных распределений, и
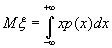 (B.036)
(B.036)
для непрерывной случайной величины.
Для существования математического ожидания достаточно, чтобы ряд в формуле (B.035) и интеграл в формуле (B.036) сходились абсолютно.
Есть распределения вероятностей, для которых не существует математического ожидания. Примером такого распределения служит геометрическая прогрессия.
M(η + ξ) = Mη + Mξ (B.037)
Maξ = aMξ (B.038)
Иначе говоря, математическое ожидание линейной комбинации случайных величин сама равна линейной комбинации математических ожиданий этих случайных величин.
Кроме среднего значения случайной величины, которое характеризует центр распределения вероятностей, часто используется характеристика «разброса» случайной величины относительно этого центра. В русскоязычной литературе этот разброс называют дисперсией и обозначают Dξ
Дисперсией Dξ случайной величины ξ называется величина
Dξ = M(ξ-Mξ)2 (B.039)
или
Dξ = Mξ2 - (Mξ)2 (B.040).
Дисперсия существует не для всех случайных величин. На практике часто вместо Dξ используют величину σ=sqrt(Dξ), которая называется средним квадратичным отклонением случайной величины xi
D(ξ + a) = Dξ (B.041)
D(aξ) = a2Dξ (B.042)
Кроме первого и второго моментов, при описании случайных величин иногда используются и другие моменты: третий, четвёртый и т.д. дадим им определения.
Для дискретной случайной величины со значениями x1, x2 ..., имеющими вероятности p1, p2,… k-m центральным моментом называется величина:
(B.043)
Для непрерывной случайной величины k-ым центральным моментом называется величина:
(B.044)
Центральные моменты не зависят от начала отсчёта в шкале измерения случайной величины, однако зависимость от масштаба величин измерений (в чём измерять: в метрах, сантиметрах) остаётся. Поэтому часто центральные моменты нормируют. Чаще всего из нормированных моментов используются:
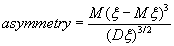 (B.045)
(B.045)
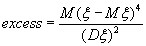 (B.046)
(B.046)
Принято считать, что асимметрия в какой-то степени характеризует симметричность распределения случайной величины, а эксцесс – степень выраженности «хвостов» распределения, т.е. частоту появления удалённых от среднего значения величин. Иногда значения асимметрии и эксцесса используются с тем, чтобы отнести выборку к данному семейству распределений, а также проверки приближённости данного случайного распределения к «нормальному» распределению.
Замечание: для любого нормального распределения асимметрия равна нулю, а эксцесс – трём. Поэтому нормальное распределение полностью определяется двумя моментами: Mξ и Dξ. О нормальном распределении можно прочитать в [далее в разделе B.5.2.2]. Смотрите также любые книги по теории вероятностей и математической статистике.
Квантилью xp случайной величины, имеющей функцию распределения F(x), называют решение уравнения:
F(x) = p (B.047)
Величину xp называют p-квантилью, или квантилью уровня p распределения F(x).
Медианой называется квантиль, соответствующая значению p = 0,5. В статистике также используются квантили с p = 95% и p = 99%, протабулированные для различных функций распределения.
Для нахождения медианы обычно не требуется сложных вычислений. Так, для нахождения медианы дискретного конечного распределения величины со значениями x1, x2, ... xk необходимо:
Для непрерывных величин, кроме тех, которые имеют нулевое значение асимметрии, значение медианы необходимо вычислять по формуле (B.047). Для непрерывной случайной величины с симметричной функцией распределения медиана равна математическому ожиданию:
ξ0,5 = Mξ (B.048).
B.3.3.3. Коэффициент корреляции
Случайные величина ξ и η независимы, если вероятность их совместного появления равна произведению вероятностей их отдельного появления на всех множествах определения случайных величин ξ и η
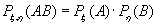 (B.049)
(B.049)
Иначе говоря, случайные величины независимы, если независимы любые события, которые выражаются этими случайными величинами.
Независимость случайных величин обеспечивается скорее схемой постановки эксперимента, чем проверкой математических соотношений.
Для независимых случайных величин справедливы соотношения:
Mξ·η = Mξ·Mη (B.050)
D(ξ + η) = Dξ + Dη (B.051)
Ковариацией cov(ξ, η) случайных величин называют:
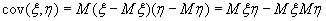 (B.052)
(B.052)
Поэтому для независимых случайных величин их ковариация равна нулю. Обратное не верно. Кроме того, для некоторых распределений случайной величины ковариации вообще не существует.
Для ковариации справедлива формула:
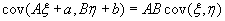 (B.053).
(B.053).
Поскольку ковариация зависит от единиц измерения случайных величин, для измерения «связанности» случайных величин используется коэффициент корреляции.
Коэффициентом корреляции случайных величин ξ и η (обозначается как ρ) называют:
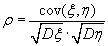 (B.054)
(B.054)
Для существования коэффициента корреляции необходимо и достаточно, чтобы Dξ > 0 и Dη > 0.
Если значения корреляции близки к значению +1 или -1, это означает, что связь между случайными величинами близка к линейной зависимости.
Важность информации, которую «передаёт» исследователю этот параметр, переоценить сложно. В качестве примера «неправильного» использования регрессии (приближения случайных величин уравнениями) в производственной сфере автор приводит пример из учебника по АСУ и АСУТП профессора Закгейма А.Ю. (у которого автор был студентом в 1989 году).
... На одном из заводов в СССР, производящих безалкогольную продукцию, решили оптимизировать издержки и улучшить качество продукции. Для этого решили провести, как это сейчас называется, маркетинговое исследование. Исследование строилось на основе регрессионных методов, данные для которых определялись на основе приведения вкусовых показателей и внешнего вида продукции по «эмпирической» шкале.
В итоге этих исследований получился противоречивый результат: чем более «зелёной» (по сравнению со стандартной жёлтой этикеткой) была этикетка на бутылке, тем выше было качество напитка.
Эта «закономерность» объяснилась очень просто. За время проведения исследований на заводе произошёл технологический сбой, повлиявший на качество напитка. Пока его ликвидировали, кончились обычные этикетки, и их срочно допечатали, случайно изменив цветовую гамму. Эту причину, которая породила «закономерность», объяснили только после проведения дополнительно «кластерного анализа» данных. Но и без него видно, что, хотя эта «закономерность» хорошо приближается прямой линией, коэффициент корреляции этих данных много меньше единицы. Именно поэтому метод регрессии здесь оказался неприменим. На рисунке B.001 приведена иллюстрация данного примера.

Рис. B.001. Пример неправильного использования метода регрессии.
На этом рисунке представлена зависимость: «цвет-качество», выраженные в условных единицах – баллах. В левом нижнем углу находится кластер данных, собранных во время технологического сбоя на заводе. В правом верхнем углу представлены данные, собранные уже после ликвидации сбоя. Как видно из графика, эти области не пересекаются между собой.
Красной линией показан результат «линейной регрессии». Не смотря на то, что экспериментальные данные хорошо «ложатся» на эту прямую линию, использование регрессии здесь неуместно.
Версия 0.09.00 alpha
05.04.2008